
Publications
Evaluating Cognitive Maps in Large Language Models with CogEval: No Emergent Planning
Felipe Vieira Frujeri*, Ida Momennejad*, Hosein Hasanbeig*, Hiteshi Sharma, Robert Ness, Nebojsa Jojic, Hamid Palangi, Jonathan Larson
in NeurIPS, 2023

We propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. And systematically evaluate cognitive maps and planning ability across eight LLMs. We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and falling in loops.
PLEX: Making the Most of the Available Data for Robotic Manipulation Pretraining
Garrett Thomas, Ching-An Cheng, Ricky Loynd, Felipe Vieira Frujeri, Vibhav Vineet, Mihai Jalobeanu, Andrey Kolobov
in CoRL, 2023

A rich representation is key to general robotic manipulation, but existing model architectures require a lot of data to learn it. Unfortunately, ideal robotic manipulation training data, which comes in the form of expert visuomotor demonstrations for a variety of annotated tasks, is scarce. In this work we propose PLEX, a transformer-based architecture that learns from task-agnostic visuomotor trajectories accompanied by a much larger amount of task-conditioned object manipulation videos — a type of robotics-relevant data available in quantity. The key insight behind PLEX is that the trajectories with observations and actions help induce a latent feature space and train a robot to execute task-agnostic manipulation routines, while a diverse set of video-only demonstrations can efficiently teach the robot how to plan in this feature space for a wide variety of tasks. In contrast to most works on robotic manipulation pretraining, PLEX learns a generalizable sensorimotor multi-task policy, not just an observational representation. We also show that using relative positional encoding in PLEX’s transformers further increases its data efficiency when learning from human-collected demonstrations. Experiments showcase PLEX’s generalization on Meta-World-v2 benchmark and establish state-of-the-art performance in challenging Robosuite environments.
PACT: Perception-Action Causal Transformer for Autoregressive Robotics Pre-Training
Rogerio Bonatti, Sai Vemprala, Shuang Ma, Felipe Frujeri, Shuhang Chen, Ashish Kapoor
in IROS, 2023
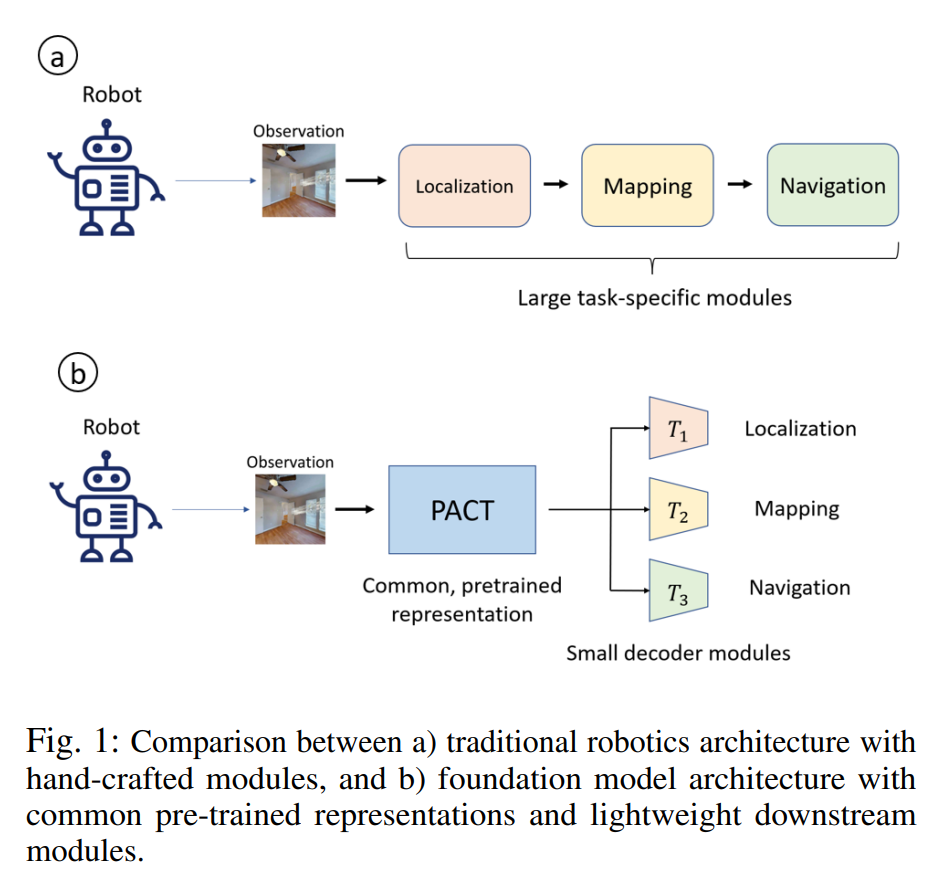
Robotics has long been a field riddled with complex systems architectures whose modules and connections, whether traditional or learning-based, require significant human expertise and prior knowledge. Inspired by large pre-trained language models, this work introduces a paradigm for pre-training a general purpose representation that can serve as a starting point for multiple tasks on a given robot. We present the Perception-Action Causal Transformer (PACT), a generative transformer-based architecture that aims to build representations directly from robot data in a self-supervised fashion. Through autoregressive prediction of states and actions over time, our model implicitly encodes dynamics and behaviors for a particular robot. Our experimental evaluation focuses on the domain of mobile agents, where we show that this robot-specific representation can function as a single starting point to achieve distinct tasks such as safe navigation, localization and mapping. We evaluate two form factors: a wheeled robot that uses a LiDAR sensor as perception input (MuSHR), and a simulated agent that uses first-person RGB images (Habitat). We show that finetuning small task-specific networks on top of the larger pretrained model results in significantly better performance compared to training a single model from scratch for all tasks simultaneously, and comparable performance to training a separate large model for each task independently. By sharing a common good-quality representation across tasks we can lower overall model capacity and speed up the real-time deployment of such systems.
HoloAssist: An Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Xin Wang*, Taein Kwon*, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Fanello, Bugra Tekin, Felipe Vieira Frujeri, Neel Joshi, Marc Pollefeys
in International Conference on Computer Vision (ICCV), 2023

HoloAssist is a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment.
Hindsight Learning for MDPs with Exogenous Inputs
Sean R. Sinclair, Felipe Frujeri, Ching-An Cheng, Luke Marshall, Hugo Barbalho, Jingling Li, Jennifer Neville, Ishai Menache, Adith Swaminathan
in International Conference in Machine Learning (ICML), 2023
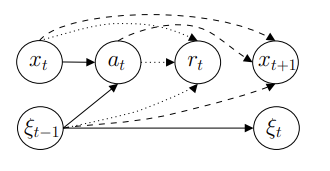
Many resource management problems require sequential decision-making under uncertainty, where the only uncertainty affecting the decision outcomes are exogenous variables outside the control of the decision-maker. We model these problems as Exo-MDPs (Markov Decision Processes with Exogenous Inputs) and design a class of data-efficient algorithms for them termed Hindsight Learning (HL). Our HL algorithms achieve data efficiency by leveraging a key insight: having samples of the exogenous variables, past decisions can be revisited in hindsight to infer counterfactual consequences that can accelerate policy improvements. We compare HL against classic baselines in the multi-secretary and airline revenue management problems. We also scale our algorithms to a business-critical cloud resource management problem — allocating Virtual Machines (VMs) to physical machines, and simulate their performance with real datasets from a large public cloud provider. We find that HL algorithms outperform domain-specific heuristics, as well as state-of-the-art reinforcement learning methods.
Fine-Tuning Language Models with Advantage-Induced Policy Alignment
Banghua Zhu, Hiteshi Sharma, Felipe Vieira Frujeri, Shi Dong, Chenguang Zhu, Michael I. Jordan, Jiantao Jiao
in Preprint, 2023
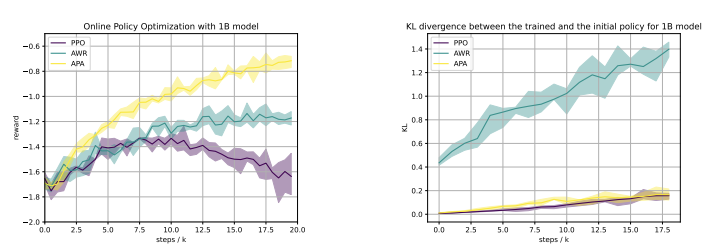
Reinforcement learning from human feedback (RLHF) has emerged as a reliable approach to aligning large language models (LLMs) to human preferences. Among the plethora of RLHF techniques, proximal policy optimization (PPO) is of the most widely used methods. Despite its popularity, however, PPO may suffer from mode collapse, instability, and poor sample efficiency. We show that these issues can be alleviated by a novel algorithm that we refer to as Advantage-Induced Policy Alignment (APA), which leverages a squared error loss function based on the estimated advantages. We demonstrate empirically that APA consistently outperforms PPO in language tasks by a large margin, when a separate reward model is employed as the evaluator. In addition, compared with PPO, APA offers a more stable form of control over the deviation from the model’s initial policy, ensuring that the model improves its performance without collapsing to deterministic output. In addition to empirical results, we also provide a theoretical justification supporting the design of our loss function.
DOTE: Rethinking (Predictive) WAN Traffic Engineering
Yarin Perry, Felipe Vieira Frujeri, Chaim Hoch, Srikanth Kandula, Ishai Menache, Michael Schapira, Aviv Tamar
in NSDI (Best Paper Award), 2023
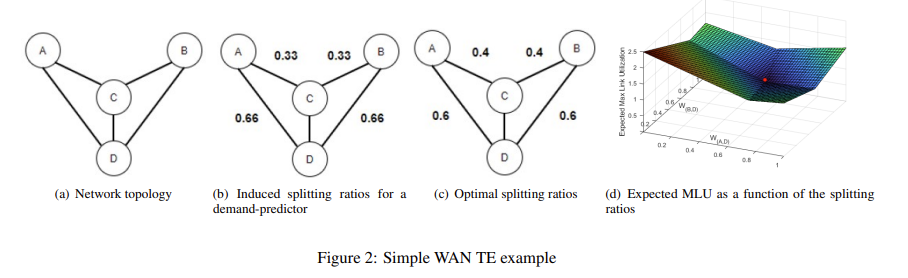
We explore a new design point for traffic engineering on wide-area networks (WANs): directly optimizing traffic flow on the WAN using only historical data about traffic demands. Doing so obviates the need to explicitly estimate, or predict, future demands. Our method, which utilizes stochastic optimization, provably converges to the global optimum in well-studied theoretical models. We employ deep learning to scale to large WANs and real-world traffic. Our extensive empirical evaluation on real-world traffic and network topologies establishes that our approach’s TE quality almost matches that of an (infeasible) omniscient oracle, outperforming previously proposed approaches, and also substantially lowers runtimes.
Towards Data-Driven Offline Simulations for Online Reinforcement Learning
Shengpu Tang, Felipe Vieira Frujeri, Dipendra Misra, Alex Lamb, John Langford, Paul Mineiro, Sebastian Kochman
in Neurips Workshop, 2022
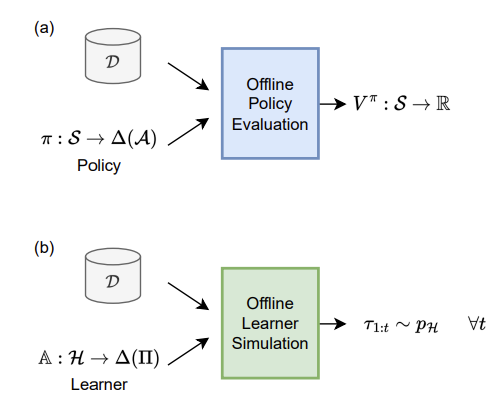
Modern decision-making systems, from robots to web recommendation engines, are expected to adapt: to user preferences, changing circumstances or even new tasks. Yet, it is still uncommon to deploy a dynamically learning agent (rather than a fixed policy) to a production system, as it’s perceived as unsafe. Using historical data to reason about learning algorithms, similar to offline policy evaluation (OPE) applied to fixed policies, could help practitioners evaluate and ultimately deploy such adaptive agents to production. In this work, we formalize offline learner simulation (OLS) for reinforcement learning (RL) and propose a novel evaluation protocol that measures both fidelity and efficiency of the simulation. For environments with complex high-dimensional observations, we propose a semi-parametric approach that leverages recent advances in latent state discovery in order to achieve accurate and efficient offline simulations. In preliminary experiments, we show the advantage of our approach compared to fully non-parametric baselines.
MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control
Nolan Wagener, Andrey Kolobov, Felipe Vieira Frujeri, Ricky Loynd, Ching-An Cheng, Matthew Hausknecht
in NeurIPS, 2022
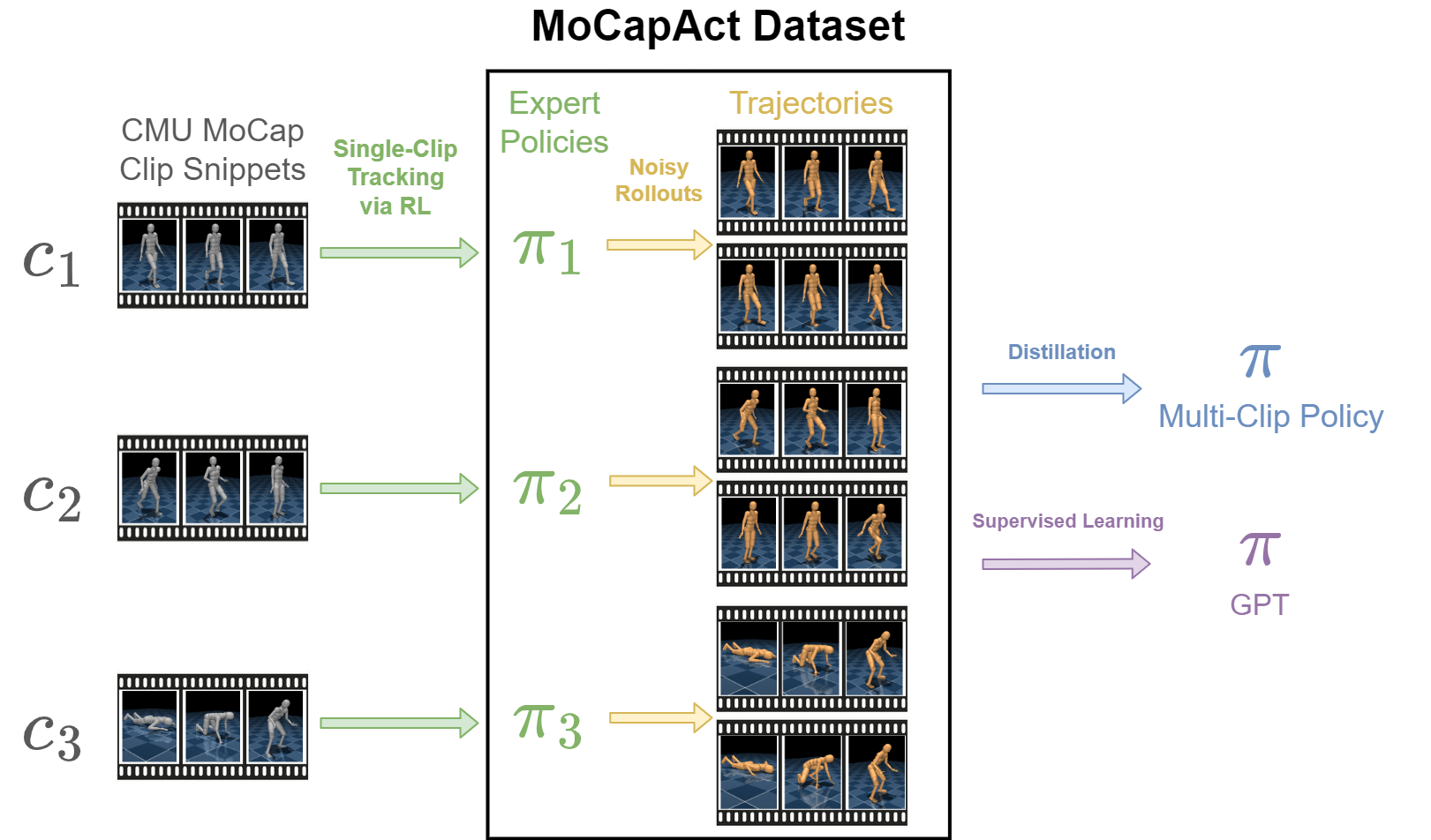
Control of simulated humanoid characters is a challenging benchmark for sequential decision-making methods, as it assesses a policy’s ability to drive an inherently unstable, discontinuous, and high-dimensional physical system. One widely studied approach is to utilize motion capture (MoCap) data to teach the humanoid agent low-level skills (e.g., standing, walking, and running) that can be used to generate high-level behaviors. However, even with MoCap data, controlling simulated humanoids remains very hard, as MoCap data offers only kinematic information. Finding physical control inputs to realize the demonstrated motions requires computationally intensive methods like reinforcement learning. Thus, despite the publicly available MoCap data, its utility has been limited to institutions with large-scale compute. In this work, we dramatically lower the barrier for productive research on this topic by training and releasing high-quality agents that can track over three hours of MoCap data for a simulated humanoid in the dm_control physics-based environment.
The Sandbox Environment for Generalizable Agent Research (SEGAR)
R Devon Hjelm, Bogdan Mazoure, Florian Golemo, Felipe Vieira Frujeri, Mihai Jalobeanu, Andrey Kolobov
in Preprint, 2022
 |  |  |
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.
Towards a Cost vs. Quality Sweet Spot for Monitoring Networks
Nofel Yaseen, Behnaz Arzani, Krishna Chintalapudi, Vaishnavi Ranganathan, Felipe Vieira Frujeri, Kevin Hsieh, Daniel S. Berger, Vincent Liu, Srikanth Kandula
in HotNets, 2021
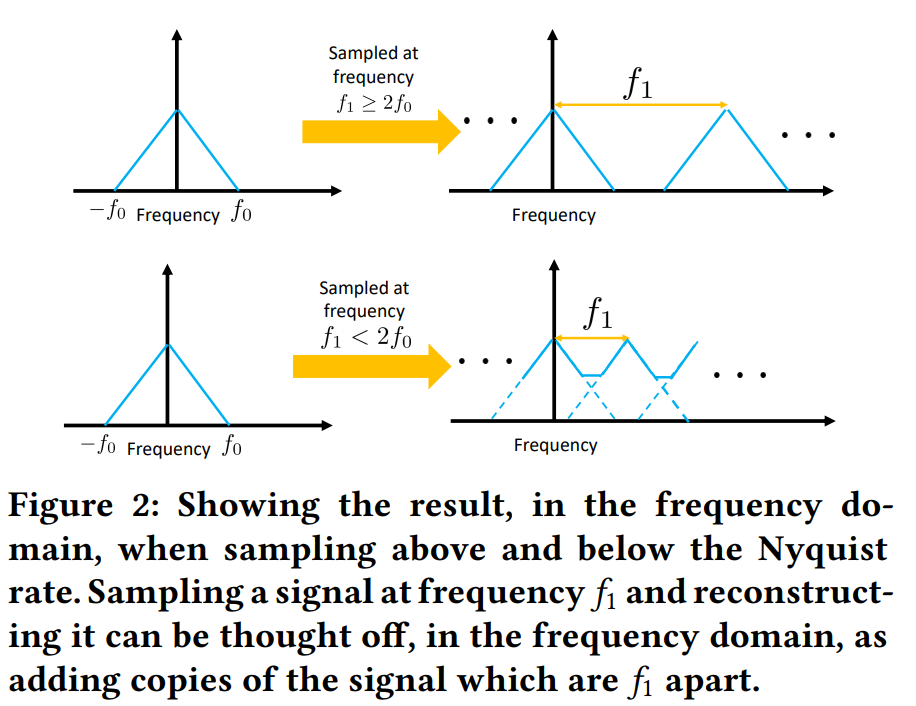
Continuously monitoring a wide variety of performance and fault metrics has become a crucial part of operating large-scale datacenter networks. In this work, we ask whether we can reduce the costs to monitor — in terms of collection, storage and analysis — by judiciously controlling how much and which measurements we collect. By positing that we can treat almost all measured signals as sampled time-series, we show that we can use signal processing techniques such as the Nyquist-Shannon theorem to avoid wasteful data collection. We show that large savings appear possible by analyzing tens of popular measurements from a production datacenter network. We also discuss the technical challenges that must be solved when applying these techniques in practice.
Prediction-Based Power Oversubscription in Cloud Platforms
Alok Kumbhare, Reza Azimi, Ioannis Manousakis, Anand Bonde, Felipe Frujeri, Nithish Mahalingam, Pulkit A. Misra, Seyyed Ahmad Javadi, Bianca Schroeder, Marcus Fontoura, and Ricardo Bianchini
in Proceedings of the USENIX Annual Technical Conference (ATC), 2021
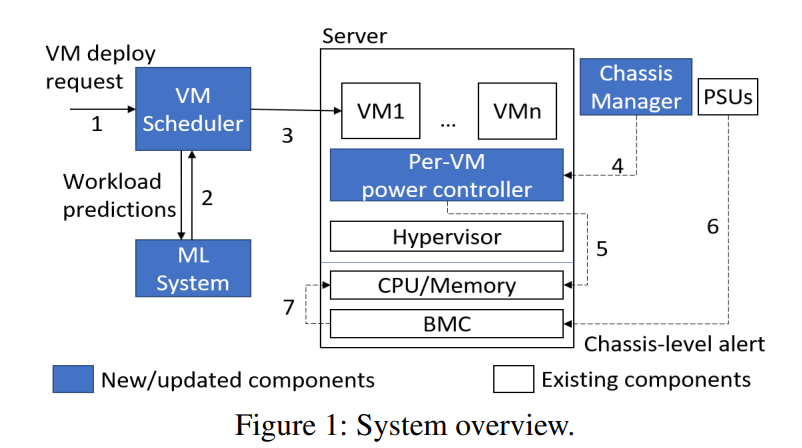
Datacenter designers rely on conservative estimates of IT equipment power draw to provision resources. This leaves resources underutilized and requires more datacenters to be built. Prior work has used power capping to shave the rare power peaks and add more servers to the datacenter, thereby oversubscribing its resources and lowering capital costs. This works well when the workloads and their server placements are known. Unfortunately, these factors are unknown in public clouds, forcing providers to limit the oversubscription so that performance is never impacted. In this paper, we argue that providers can use predictions of workload performance criticality and virtual machine (VM) resource utilization to increase oversubscription. This poses many challenges, such as identifying the performance-critical workloads from black-box VMs, creating support for criticality-aware power management, and increasing oversubscription while limiting the impact of capping. We address these challenges for the hardware and software infrastructures of Microsoft Azure. The results show that we enable a 2x increase in oversubscription with minimum impact to critical workloads.
Providing SLOs for Resource-Harvesting VMs in Cloud Platforms
Pradeep Ambati, Íñigo Goiri, Felipe Vieira Frujeri, Alper Gun, Ke Wang, Brian Dolan, Brian Corell, Sekhar Pasupuleti, Thomas Moscibroda, Sameh Elnikety, Marcus Fontoura, Ricardo Bianchini
in Proceedings of the Symposium on Operating Systems Design and Implementation (OSDI), 2020
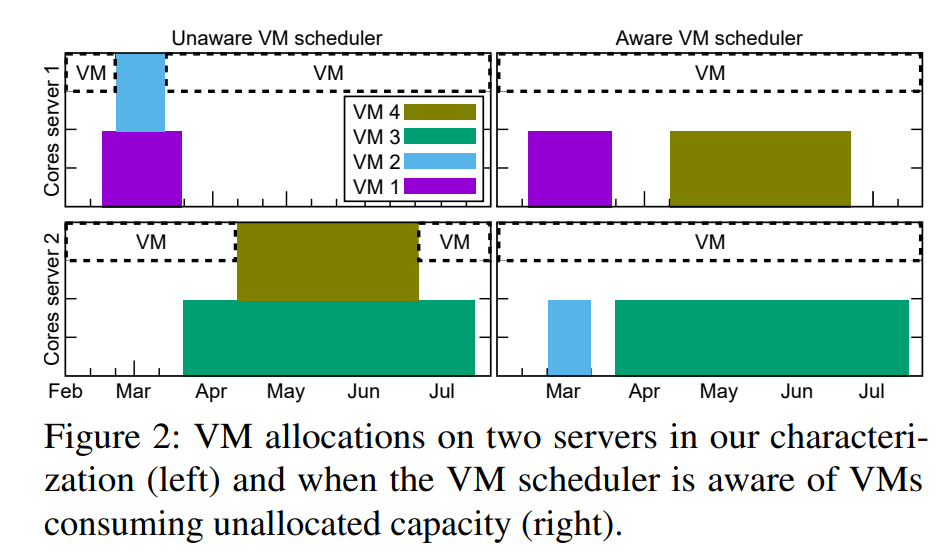
Cloud providers rent the resources they do not allocate as evictable virtual machines (VMs), like spot instances. In this paper, we first characterize the unallocated resources in Microsoft Azure, and show that they are plenty but may vary widely over time and across servers. Based on the characterization, we propose a new class of VM, called Harvest VM, to harvest and monetize the unallocated resources. A Harvest VM is more flexible and efficient than a spot instance, because it grows and shrinks according to the amount of unallocated resources at its underlying server; it is only evicted/killed when the provider needs its minimum set of resources. Next, we create models that predict the availability of the unallocated resources for Harvest VM deployments. Based on these predictions, we provide Service Level Objectives (SLOs) for the survival rate (e.g., 65% of the Harvest VMs will survive more than a week) and the average number of cores that can be harvested. Our short-term predictions have an average error under 2% and less than 6% for longer terms. We also extend a popular cluster scheduling framework to leverage the harvested resources. Using our SLOs and framework, we can offset the rare evictions with extra harvested cores and achieve the same computational power as regular-priority VMs, but at 91% lower cost. Finally, we outline lessons and results from running Harvest VMs and our framework in production.
Scouts: Improving the Diagnosis Process Through Domain-customized Incident Routing
Jiaqi Gao, Nofel Yaseen, Robert MacDavid, Felipe Vieira Frujeri, Vincent Liu, Ricardo Bianchini, Ramaswamy Aditya, Xiaohang Wang, Henry Lee, Dave Maltz, Minlan Yu, Behnaz Arzani
in SIGCOMM , 2020
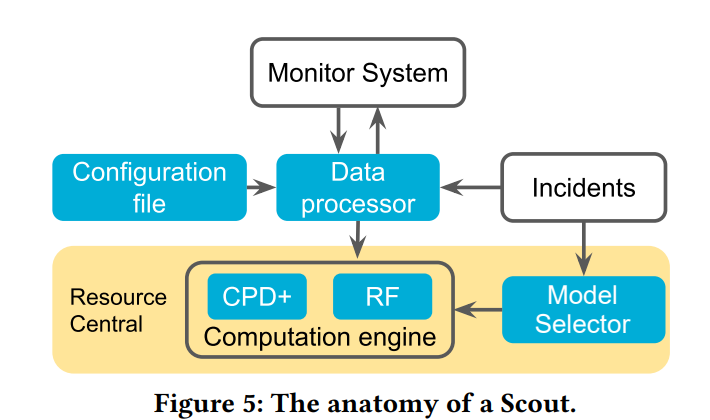
Cloud providers rent the resources they do not allocate as evictable virtual machines (VMs), like spot instances. In this paper, we first characterize the unallocated resources in Microsoft Azure, and show that they are plenty but may vary widely over time and across servers. Based on the characterization, we propose a new class of VM, called Harvest VM, to harvest and monetize the unallocated resources. A Harvest VM is more flexible and efficient than a spot instance, because it grows and shrinks according to the amount of unallocated resources at its underlying server; it is only evicted/killed when the provider needs its minimum set of resources. Next, we create models that predict the availability of the unallocated resources for Harvest VM deployments. Based on these predictions, we provide Service Level Objectives (SLOs) for the survival rate (e.g., 65% of the Harvest VMs will survive more than a week) and the average number of cores that can be harvested. Our short-term predictions have an average error under 2% and less than 6% for longer terms. We also extend a popular cluster scheduling framework to leverage the harvested resources. Using our SLOs and framework, we can offset the rare evictions with extra harvested cores and achieve the same computational power as regular-priority VMs, but at 91% lower cost. Finally, we outline lessons and results from running Harvest VMs and our framework in production.